
When we talk about Privacy Enhancing Techniques (PETs) we often don’t consider what we really mean by “privacy”. We often miss the nuance that “privacy” can come in many different shapes and sizes. Understanding different types of privacy and how to measure them allows us to ensure our data is secure for a given application and can help us select the right PETs to achieve appropriate levels of privacy
Privacy is not a binary concept where a data set is either “private” or not but a much more nuanced idea. Luckily we can measure and quantify different types of privacy. To achieve both high levels of utility and privacy in your data, you need to understand the levels of privacy achieved with each PET application. This allows the trade-off between privacy and utility to be optimised for a given application. While there are large amounts of ways to analyse and quantify the privacy of data sets, there are a few key privacy models that are important to understand.
Our data set
To further explain these privacy models we are going to demonstrate them on an example data set. We can classify each "column" or attribute of this data set as either being a sensitive attribute (SA), identifying (ID), quasi-identifying (QID), or non-sensitive (NS). Generally, SAs are the thing that we are trying to protect, but are often also the attributes that we are hoping to analyse. IDs are direct identifiers (passport numbers, full names, etc.). QIDs on the other hand are attributes such as age and gender that relate to a person. While QIDs are not directly identifying, if a number of them are combined they can be used to identify an individual. For example, it has been shown that it is possible to identify about 87% of the US population by only using their zip code, age, and gender.
Our data set shows what political parties an individual voted for. To improve the privacy of our data we have applied a masking PET to the "Names" and a generalisation PET to the "Age".
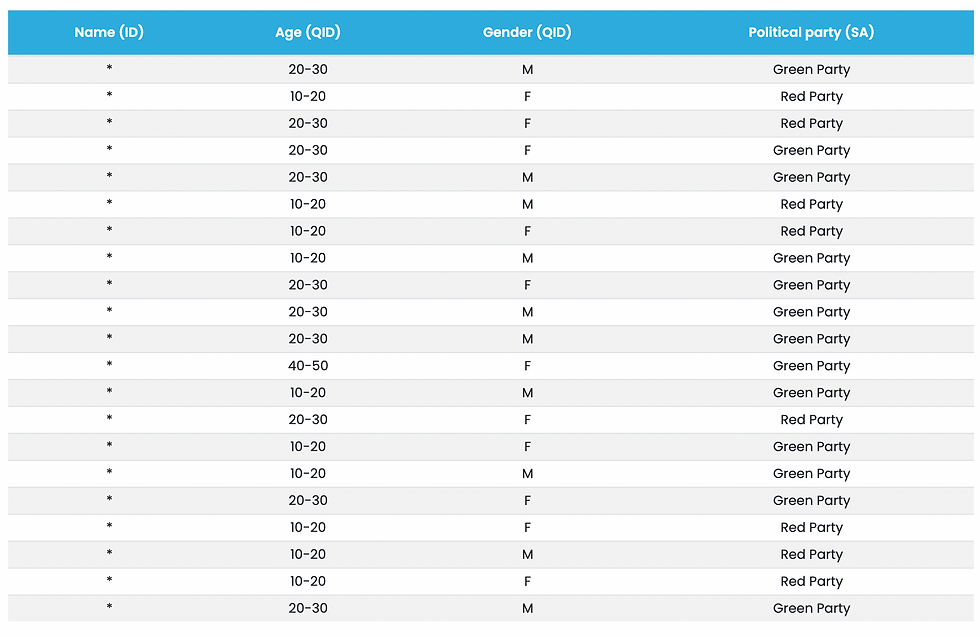
We now also consider a possible attack on the protected data using linkage. This is where the attacker knows an individual is included in the data set and has some information about that individual. This sort of information can be gathered from all kinds of public data sources. In this instance, this information might have come from a voter registry.
Attack table

K-anonymity
I-diversity
t-closeness
Ɛ-differential